Self-initiated study and open ontology
FAIR Dataset Contracts for Scientific Data
We turned "is this dataset actually reusable?" into a machine-checkable question, ran it across 1,738 real published biomedical datasets from three major repositories, and then built the open ontology that models the layer they are missing. The result is a measured gap between data that is deposited and data that is AI-ready, and a validated model for closing it.
1,738
Real datasets analysed (3 repositories)
0%
Interoperable or AI-ready
100%
Lack a machine-readable schema
The gap: findable is not the same as reusable
As research organisations move data closer to AI systems, the constraint is rarely the science and often the plumbing: whether a computational output can be reliably found, assembled, trusted and reused without bespoke manual wrangling for every project. A dataset can carry a DOI, a title and a landing page, and still be impossible for a machine to reuse, because the metadata that automation depends on is absent. FAIR (Wilkinson et al., 2016) named the principles; frameworks such as FAIRSCAPE (Al Manir, Clark et al.) and the Bridge2AI metadata work (Caufield, Munoz-Torres et al.) have since defined what AI-ready biomedical data should look like. What has been missing is a simple, open way to check a dataset against those expectations, and a shared model of what "AI-ready" concretely requires.
The study: 1,738 real datasets, four FAIR tiers
We assembled 1,738 real public datasets (single-cell, proteomics, spatial and multi-omics) from three major repositories, EMBL-EBI BioStudies (798), Dryad (340) and PRIDE / ProteomeXchange (600), normalised their metadata across profiles, and validated each against a tiered contract that operationalises the 28 FAIRSCAPE criteria. Findability is anchored on a persistent identifier, title and description; keywords and licence are reported as sub-metrics.
| FAIR tier | Datasets conforming |
|---|---|
| Findable (PID, title, description) | 99.9% |
| Accessible (machine-readable distribution) | 91.3% |
| Interoperable (machine-readable schema, version) | 0.0% |
| AI-ready (checksums, provenance, data dictionary) | 0.0% |
Datasets are overwhelmingly findable and mostly accessible, but not one of the 1,738 is interoperable or AI-ready. The whole corpus is missing the machine-readable structural and provenance layer that automated assembly, trust and AI reuse depend on: no dataset carries a machine-readable schema, integrity checksums, or provenance, and about 80% lack a version identifier. Every DOI, HTTP status and per-dataset result is recorded in the repository, so the analysis is fully reproducible.
The remedy: an open, certified ontology
Measuring the gap is not enough, so we built the model that fills it: an OWL 2 ontology (far:, the FAIR AI-Ready Dataset ontology) that defines what a dataset needs to be a reusable, AI-ready data product, a machine-readable schema, provenance, integrity checks, a data dictionary, an ethics basis and access specification. Rather than reinvent vocabulary, it composes and aligns to existing standards, with 42 alignment mappings to schema.org, W3C DCAT and PROV-O, SPDX, Bioschemas and MLCommons Croissant. The SHACL tiers are its validation layer, so the diagnostic and the remedy are one coherent artifact.
The ontology is checked through our open-source Open Ontologies engine: it validates cleanly and, under OWL-RL reasoning (238 asserted triples closing to 705 inferred), surfaces no logical inconsistencies.
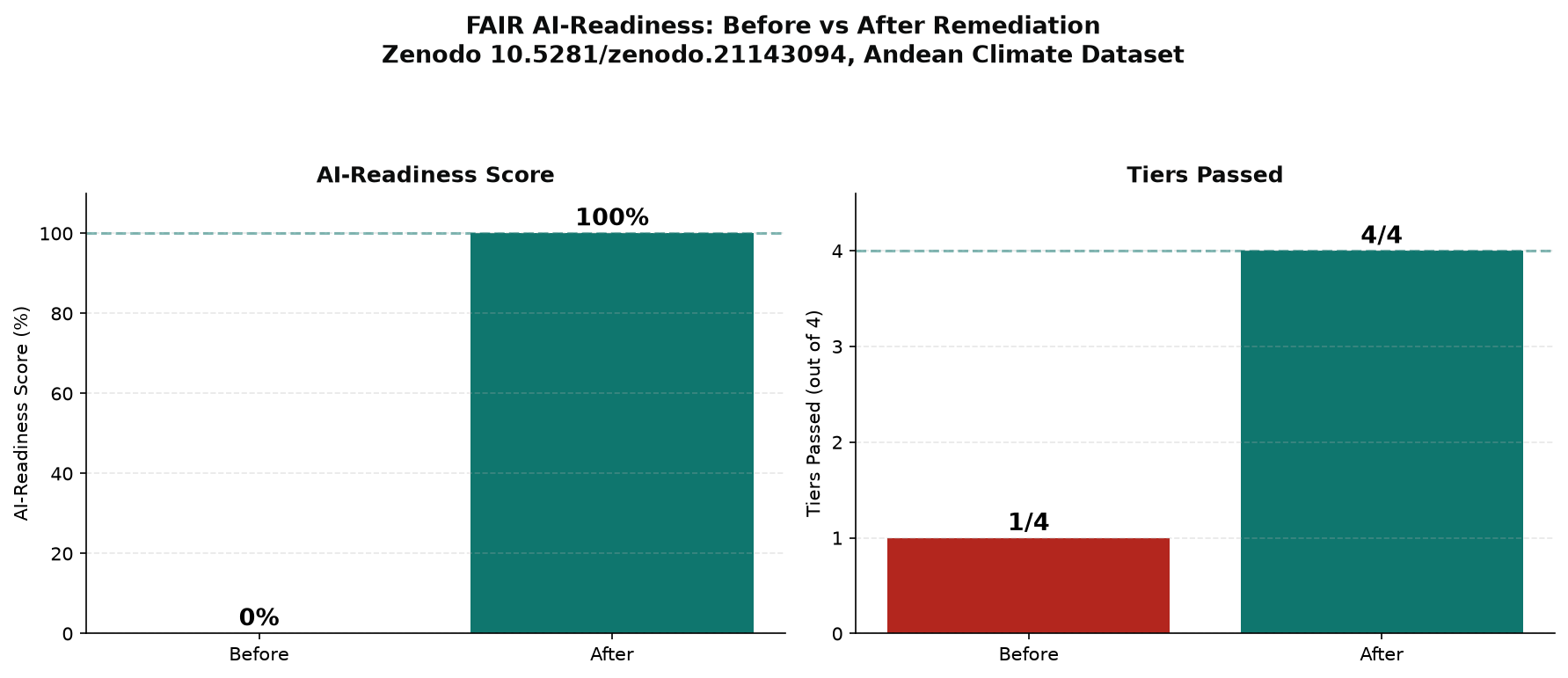
From 0 to 100%: we do not just measure the gap, we close it
To prove the model works, we took a real open dataset from 0% to 100% AI-ready. The Zenodo Andean climate dataset (a dense high-Andean weather-station network in southern Ecuador) is findable and accessible but, like the rest of the corpus, fails the machine-readable layer: 0% AI-ready in its published form. Using the ontology and toolkit, we enriched it with values derived entirely from the dataset itself: a real SHA-256 integrity checksum, a variable schema and data dictionary built from its 12 real columns, a sample count from its 226 rows, a machine-readable provenance record, and a controlled-vocabulary subject. The enriched record then passes all four tiers, with zero violations against the same published SHACL contract.
The full study and this worked remediation are written up in a short report: read the report (PDF) (opens in new tab).
Why it matters for research data platforms
For any organisation building an AI-ready data platform, whether a biotech scaling multi-omics or a public research programme, the distance between "we deposited it" and "a machine can find, assemble and trust it" is precisely this contract layer. Making that layer explicit, modelled and testable is what turns scattered pipeline outputs into governed, reusable data products, with structure, provenance, versioning and access that hold up to reuse and, later, to regulated use.
Open toolkit and how we work
The ontology, the tiered SHACL contract, the validator, the readiness rubric and the full 1,738-dataset analysis are open source under an MIT licence. You can run the contract against your own datasets in minutes.
github.com/fabio-rovai/fair-scientific-dataIf you are building or governing a scientific data platform and want the dataset-contract, provenance and metadata layer done properly, we would be glad to talk. Contact us at fabio@thetesseractacademy.com or see how to work with us.
Sources and grounding: Wilkinson et al., The FAIR Guiding Principles (Scientific Data, 2016); Al Manir, Clark et al., FAIRSCAPE AI-readiness framework; Caufield, Munoz-Torres et al., Bridge2AI metadata standards (arXiv:2509.10432); Leo, Soiland-Reyes et al., Workflow Run RO-Crate provenance (PLoS One, 2024); W3C DCAT and PROV-O; MLCommons Croissant. Analysis run 2 July 2026 on 1,738 public datasets from EMBL-EBI BioStudies, Dryad and PRIDE / ProteomeXchange.